Немного теории о том как планировать очередность задач - с реальными расчётами. Писано DevOps/Cloud/Platform инженером, системным администратором.
Ситуация:
- Бэкенд-команда написала вчера вечером: CI/CD снова сломался на деплое в dev. Уже третий раз за неделю. Два часа потеряли, пока разбирались.
- QA написали утром: нужно новое окружение под тестирование фичи. Нестандартная конфигурация, обычным namespace не обойтись. У них есть дедлайн - через две недели релиз.
- Продакт-менеджер зашёл в Slack пять минут назад: “Когда будет готово окружение для QA? Они без него стоят.”
- И ещё есть задача из прошлого спринта - настроить алертинг для нового сервиса. Никто не давит, но технический долг растёт.
Итого: четыре задачи. Всё срочно. С чего начать?
Интуиция здесь может не помочь. (Кстати, для интереса - запишите/запомните свой вариант перед тем как читать дальше).
Давайте разбираться в деталях теории. Ну вдруг ваша интуиция еще не натренирована?
Шаг первый: не всё одинаково срочно
Первое что нужно сделать с любым входящим запросом - это не считать его. Это его отсортировать.
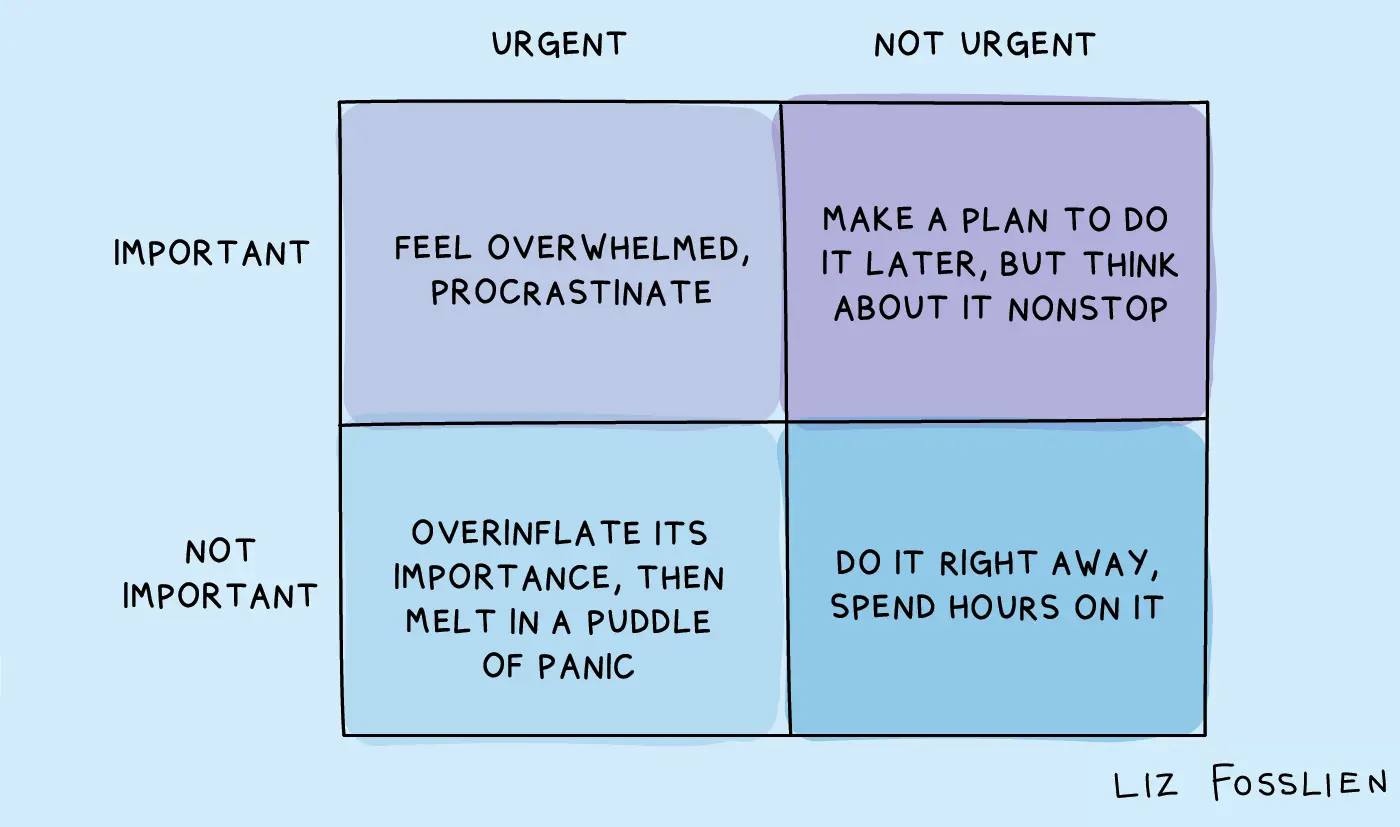
Матрица Эйзенхауэра делит задачи по двум осям: важно/неважно и срочно/несрочно. Четыре квадранта.
Квадрант I - Важно и срочно. CI/CD сломан в проде прямо сейчас, команда стоит. Прод упал. Делаешь без фреймворков, без расчётов, сразу.
Квадрант II - Важно, но не срочно. Большинство инфра-задач живут здесь. Настроить алертинг. Пофиксить нестабильный CI/CD. Написать документацию. Это задачи которые определяют качество работы, но никто не стоит над душой. Именно поэтому они вечно откладываются - и потом превращаются в Квадрант I.
Стивен Кови называл это “Квадрант II проблема”: важное несрочное всегда проигрывает срочному неважному.
Квадрант III - Срочно, но не важно. “Срочно дай SSH-доступ.” “Срочно посмотри почему у меня не работает локально.” Если решается за пять минут - решаешь. Если нет - делегируешь или переносишь.
Квадрант IV - Не важно и не срочно. “Попробовать новый инструмент для интереса.” Не выбрасываешь - переносишь на паузы между задачами. Это инвестиция в себя, которая окупается, просто не сегодня.
Возвращаемся к нашей ситуации.
CI/CD в dev падает каждый третий деплой - Квадрант II. Не прод, команда не стоит прямо сейчас, но теряет два часа каждые два дня.
QA нужно окружение - Квадрант II. Есть дедлайн через две недели, сегодня не блокирует.
Продакт давит в Slack - это не новая задача, это давление по уже существующей.
Алертинг - Квадрант II. Никто не давит.
Все три задачи в одном квадранте. Идем дальше.
Шаг второй: что важнее - считаем
RICE Framework придумали в Intercom для приоритизации продуктовых фич. Для инфра-задач он тоже работает.
Формула: RICE = (Reach × Impact × Confidence) / Effort
Reach - сколько людей затронет задача за квартал. Для инфра я считаю не конечных пользователей (откуда мне их знать), а внутренних - команды разработки.
Impact - насколько сильно. Шкала: 0.25 (минимальное) / 0.5 / 1 / 2 / 3 (массивное). Самый сложный параметр. Помогает думать категориями: тормозит работу, бесит, блокирует, меняет приоритеты всей команды?
Confidence - насколько уверен в своих оценках. 100% / 80% / 50%. Если задача мутная и непонятная - confidence низкий, и итоговый score справедливо падает.
Effort - в моих человеко-месяцах. Один месяц = 160 часов. 4 часа = 0.025 человеко-месяца.
Считаем CI/CD:
Reach: 10 деплоев в неделю, падает каждый третий - 30+ инцидентов за квартал. В каждом 1-2 человека. Итого: 30 человеко-инцидентов.
Impact: Первый порыв - поставить 1, “ну dev, не прод”. Но накопительный стресс от повторения растёт. На квартальном ревью команда скажет “инфра не работала”. Ставлю 1.5 - между средним и высоким.
Confidence: Понимаю где искать причину. 80%.
Effort: Я разберусь за 4-8 часов. Бэкенд-команда сама - 20+ часов проб и ошибок. Беру 8 часов = 0.05 человеко-месяца.
RICE = (30 × 1.5 × 0.8) / 0.05 = 720
Считаем QA окружение:
Reach: Сейчас 2 QA. Если автоматизировать - 5 человек регулярно. Для этого расчёта: 2 человека.
Impact: Критично для этого релиза, но у QA есть другие задачи пока. 2.
Confidence: Понятно что делать. 90%.
Effort: IaC уже есть, настройка займёт 4 часа = 0.025 человеко-месяца для незнакомого с окружением, или джуна. 1 час для меня = 0.00625
RICE = (2 × 2 × 0.9) / 0.025 = 144 RICE = (2 × 2 × 0.9) / 0.00625 = 576
Но никого незнакомого у нас нет, есть только я. Поэтому берем 576.
CI/CD против QA окружения: 720 против 576. Даже не в два раза, но с перевесом в сломанный CI/CD.
Теперь у меня есть число. Я могу показать его продакту который давит в Slack. Не “я так решил”, а “вот расчёт - CI/CD обходится команде дороже”. (Вы в это верите?)
Шаг третий: а если дедлайн завтра? Или еще что-то что мы не учли?
Вот где RICE надо либо пересчитывать, либо использовать что-то другое.
Представь: продакт говорит что QA нужно окружение не через две недели, а через два дня. Фича попала в приоритет, всё сдвинулось.
RICE не изменится. CI/CD всё равно 720, QA всё равно 576. (А хотя… Reach-то поменяется - QA не сами по себе, они же делают это зачем-то. Разработчикам надо поправить найденное… Задача со звёздочкой - пересчитайте RICE для обновленного дедлайна.)
Здравый смысл сомневается. Да и вообще, пора рассказать о третьем инструменте.
WSJF (Weighted Shortest Job First) - фреймворк из Scaled Agile. Смотрит не на ценность задачи, а на Cost of Delay - что ты теряешь каждый день пока не сделал.
Формула: WSJF = Cost of Delay / Job Duration
Cost of Delay складывается из трёх компонентов:
- Ценность для команды/бизнеса
- Временная критичность (есть ли дедлайн, окно возможности)
- Снижение рисков или открытие возможностей
CI/CD: теряем 2 часа инженерного времени каждый второй день. Умножаешь на стоимость часа - получаешь реальные деньги. Нет жёсткого дедлайна, но потери идут прямо сейчас. Cost of Delay накапливается.
QA окружение (в новом сценарии с дедлайном через 2 дня): 2 дня = 16 рабочих часов. Задача займёт 4 часа. У QA останется 12 часов на тестирование. Если не сделать сегодня - они не успеют к релизу. Cost of Delay: высокий и конкретный.
По WSJF - сначала QA окружение. Потому что каждый час промедления сжимает окно тестирования.
Вот что WSJF видит, а RICE - нет: разницу между “задача теряет ценность каждый день” и “задача ждёт своего момента, а пока не блокирует никого”.
Для CI/CD Cost of Delay постоянный. Для QA окружения - нулевой, пока не наступил дедлайн. После - резкий.
Как это работает вместе
Три инструмента, три уровня:
Эйзенхауэр - фильтр при входящем. Прод горит - делаю сразу. Всё остальное - сортирую в квадранты.
RICE - планирование спринта или квартала. Есть 10 задач в Квадранте II, нужно выбрать топ-3 в работу. Считаю score, сортирую.
WSJF - выбор прямо сейчас. Две задачи с похожим весом, обе могут подождать - но у одной дедлайн завтра. WSJF покажет которую делать первой.
И четвёртый случай - никакой фреймворк. Прод горит. Просто чиню.
Что я понял для себя
Когда-то давно читал книгу “Тайм-менеджмент для системного администратора” Томаса Лимончелли. Из неё в голове осел один принцип - и всё время помогал на практике: создание пользователя в системе задача не срочная, но занимает пять минут и разблокирует другого человека. Сделай сейчас, не жди конца дня. Маленькая задача с непропорционально большим эффектом.
Интуиция работает. У нее могут быть слепые пятна, но это из-за недостатка опыта.
Например когда задачи одного веса и опыта не хватает. Интуиция - это как черный ящик, который выполняет все эти расчёты, но прячет их от тебя. Ты получаешь результат, но цепочка вычислений скрыта. Она видит накопленный Cost of Delay, если ты про него знаешь.
Но она не даёт аргумент в разговоре с менеджером.
Фреймворки не умнее интуиции. Они структурируют то, что интуиция делает скрыто. Делают решение объяснимым - для команды, для менеджера, для себя через месяц.
Лучший ответ на “как расставляешь приоритеты” - не названия фреймворков. А умение объяснить почему именно эта задача сейчас, а не та.
Возвращаемся к изначальной ситуации.
Три задачи. Бэкенд, QA + продакт в Slack, алертинг.
Мой порядок: CI/CD → QA окружение → алертинг. Если у QA дедлайн завтра - меняю местами первые два.
Продакту в Slack отвечаю: “QA окружение - к обеду будет. (завтрашнему)”
Не “я решил так”. А “вот почему”.
Делаю аудит IT-инфраструктуры. Нахожу что тормозит - до инцидента. itaudit.yushkov.org
Картинка: Liz Fosslien