Создатели и поддерживающие
Всю жизнь в поддержке, завидовал тем кто создаёт. Оказалось инфраструктура — это и есть моё. Строю с нуля: бесплатно или за деньги.
IT-инфраструктура · DevOps · Облака
Всю жизнь в поддержке, завидовал тем кто создаёт. Оказалось инфраструктура — это и есть моё. Строю с нуля: бесплатно или за деньги.
Два способа закрыть порт в AWS NACL. Почему "очевидный" подход ломается при масштабировании, и причём здесь stateless природа NACL.
Построил свою статус-страницу на метриках. Про то почему алерты - полумера, и как автоматизировать действие вместо уведомления. Без ИИ.
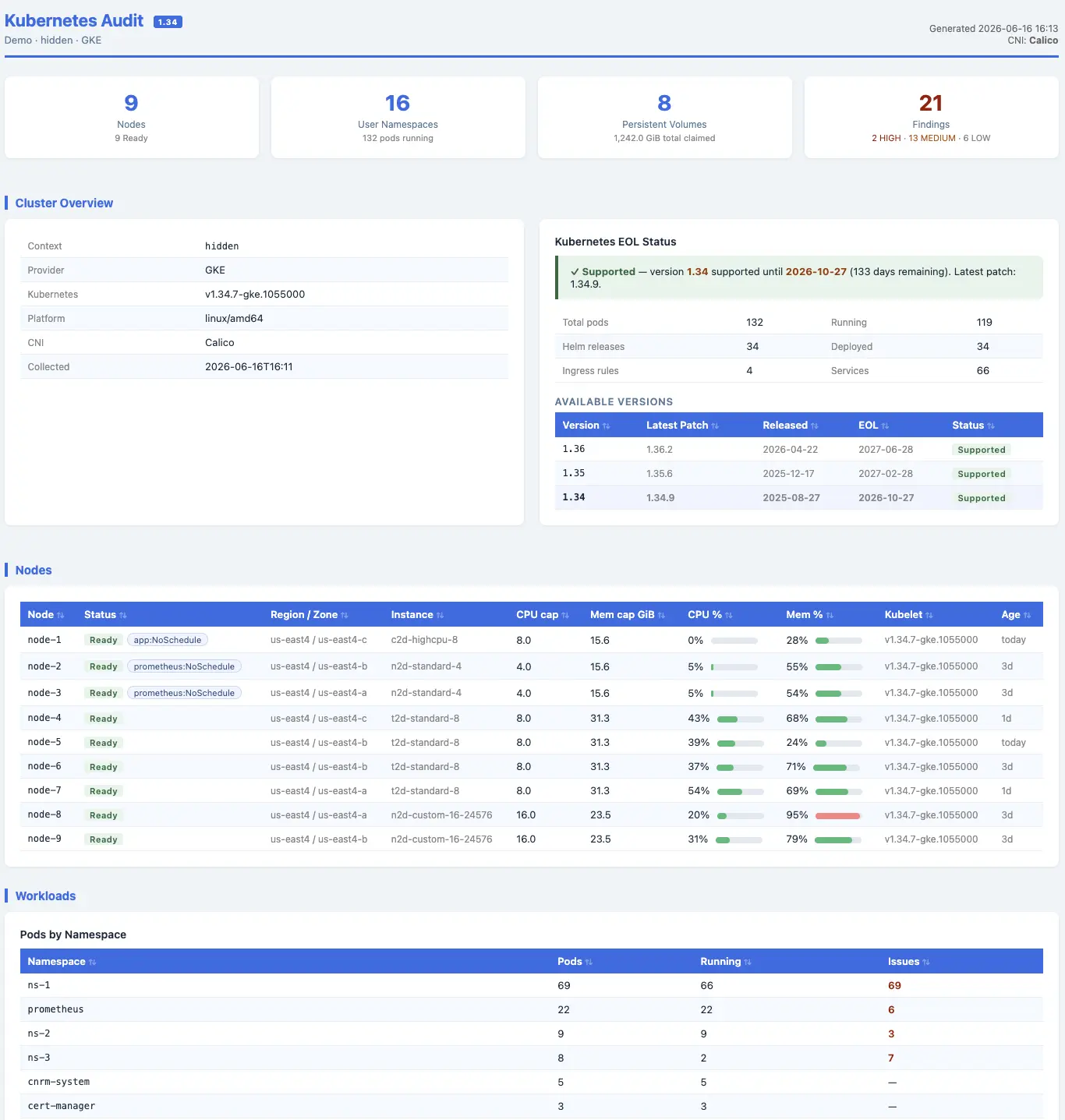
Разовый слепок k8s кластера без мониторинга и долгих настроек. Скрипт показывает что сомнительно — прямо во время созвона с клиентом.
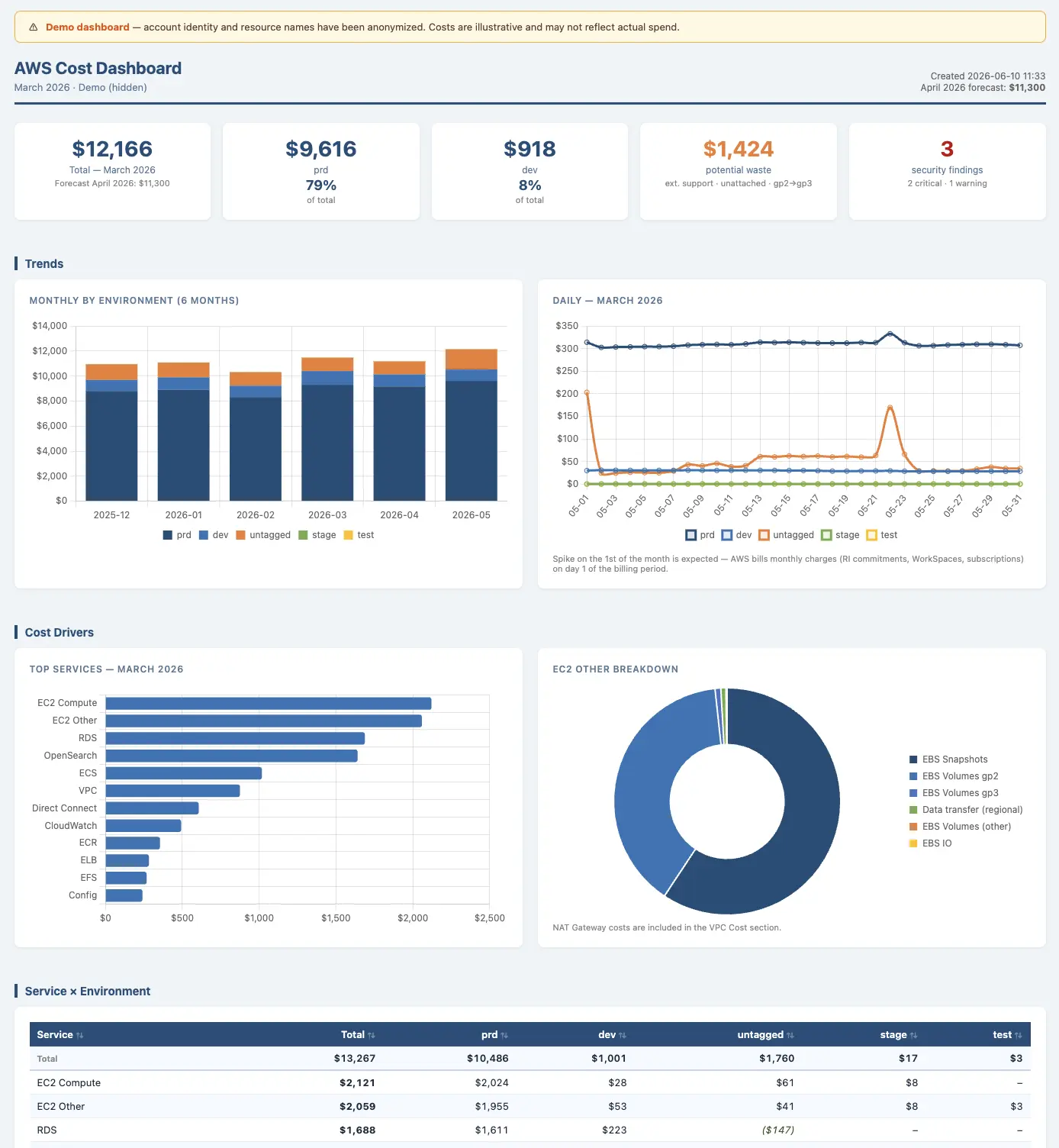
Разовый снимок AWS-инфраструктуры — сразу видно где утекают деньги. Без погружения в биллинг, без страха уронить прод. Ни один клиент не ушёл без находки.
Три типа владельцев бизнеса: успешные, загибающиеся и "так себе". Потратил неделю на третий тип. Их ответ: "это должно было быть в рамках контракта".
Попросили рассказать о самых запомнившихся проектах. Звёздной истории нет. Стартап, серверлесс, два девопса, пара месяцев. Просто обычная работа.
Пытался объяснить взрослому современному человеку что такое сервер и облако - безуспешно. Как объяснить IT без терминов и лекций?
От диска D и образов винды до контейнеров — одна и та же идея, двадцать лет спустя.

Обновил OKE кластер с 1.26 до 1.33. Жёсткие нодпулы, ручная настройка AZ, 14 минут даунтайма на ноду. Через 4 часа - решил остановиться.
Вы дали ИИ root-права? и чему вы удивляетесь?
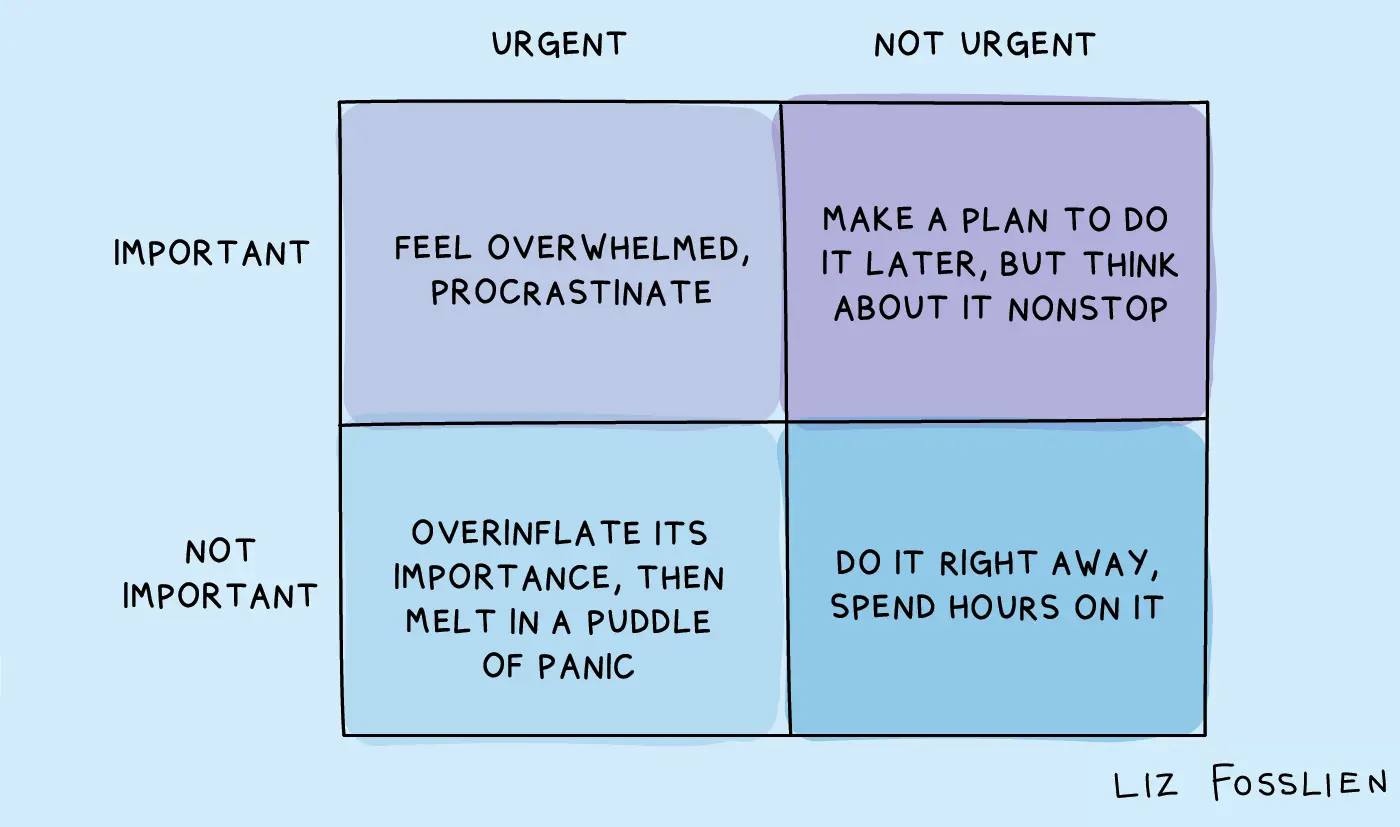
Матрица Эйзенхауэра, RICE и WSJF — три фреймворка приоритизации с реальными примерами из моего опыта. Когда интуиции не хватает для разговора.
Вы сделали чтобы работало, отлично! Давайте теперь сделаем чтобы оно работало надежно и выгодно.

Мистер Коди из Трассы 60 записывал лжецов в книжечку. «Все говорят» в LinkedIn - та же ложь: нет данных, только хайп.
Реальный кластер: только мониторинг занимает 20+ подов и 9.5 GB RAM. Что «бесплатный» Prometheus стоит на самом деле - в ресурсах, времени и внимании.
Как ботнет, взрыв метрик и один дашборд положили HA мониторинг на Thanos — каждую реплику по очереди.
Переезд с S3 может не окупиться никогда.
Когда приходит сигнал "прод упал" — первый вопрос не "что смотреть", а "какой именно прод". И почему AWS тут ни при чём.
Если о падении прода вы узнали от клиента — у вас не продакшен, а MVP.
Как одна строка в Helm values запустила бесконечный цикл исключений, забила диск и положила managed БД на OVH. Бэкап был. Повезло.
Им нужен Kubernetes. Это не мнение - я проверил.
Компания платила $7 000 в месяц за два инструмента мониторинга на AWS. Причина: никто не задавал вопрос пять лет.
Критиковал чарты Bitnami за сложность - пока сам не написал свой. Десять итераций, и вот уже 220 строк. Универсальность стоит сложности.
Потратил 2 часа делать правильно: CodeBuild, Terraform, VPC endpoints. Потом посчитал. Правильное решение стоило дороже самой проблемы.
Обновление нод кластера — не одна команда. Drain, upgrade, uncordon — одна нода за раз. И всё это в голове у одного человека.
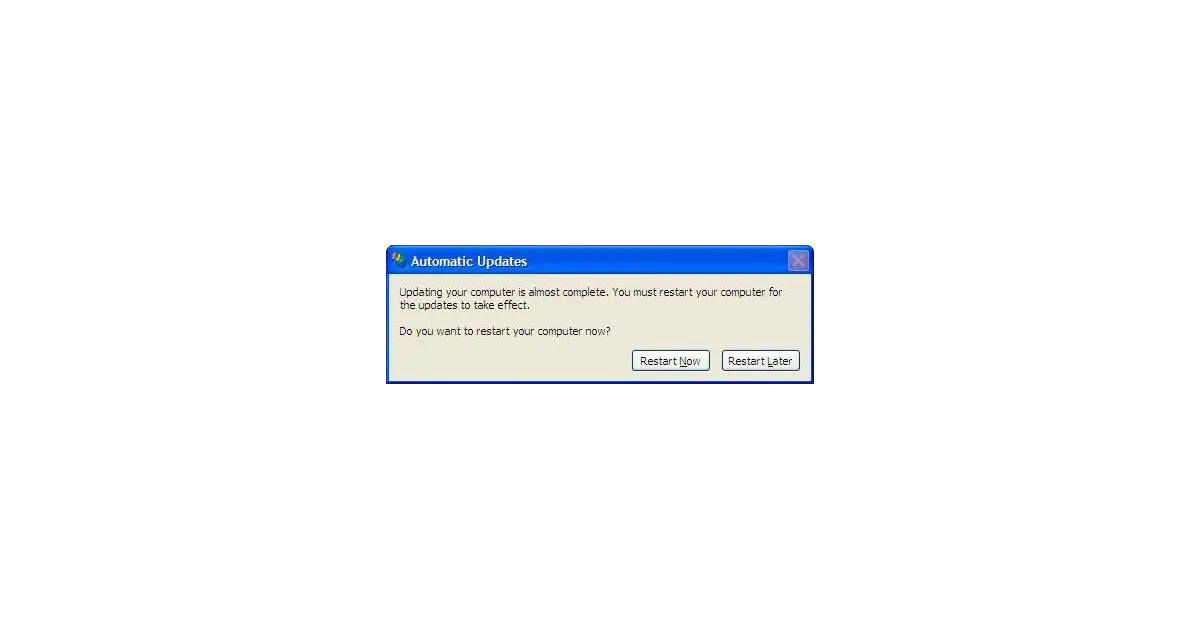
Обновление инфраструктуры — это не кнопка.
От бабушкофона в MS Authenticator до исчезнувшего /usr/bin/python — обновления ломают. Это не лень. Это выученная боль.
Когда соглашаешься на низкую ставку, цена определяет отношение — в обе стороны. Система которую я выработал.

Никто не смотрел внутрь два года. Незачем было. Я посмотрел - там жил призрак уволенного коллеги. Он ушёл. Скрипты - остались.

Когда FinOps инженер реально окупается? Математика, проблема полномочий и что делать, если расходы на облако меньше $500k в год.
Руководство в стиле Григория Остера - как сделать жизнь коллег невыносимой и обеспечить себе вечную незаменимость.

Как предпочтения PM обошлись стартапу в $2000 в год - и почему это всё равно не было провалом.
ECS против EKS: реальная стоимость - $73/мес фиксированно за control plane и 20-30% времени команды на поддержку вместо фич.
Как жёсткий лимит App Runner в 120 секунд сломал видеостриминг, стоил неделю переделок и заставил смотреть на ECS и Cloud Run.
CA-сертификат на VPN-серверах протух тихо - без мониторинга, без алертов. Как проверить свои сертификаты и настроить алерты до инцидента.

Копипаста Kubernetes-конфигов привела к падению прода. Сравнение Helm, Kustomize и гибридного подхода - ошибки деплоя снизились на 80%.

Два реальных инцидента: лимит коннектов к БД убил прод без ошибок и предупреждений. Почему connection pooling и мониторинг - не опция.

Dev-версия зависимости в проде уронила прод через 2 дня. Почему надёжный CI/CD требует автоматических проверок, а не надежды на то, что все помнят правила.

Один API, 15 млн запросов: AWS Lambda $33 против GCP Cloud Functions $16. Реальный расчёт и почему архитектура экономит больше, чем выбор провайдера.

Пароль LDAP-админа в git-репозитории в переменной PASSWORD. Почему секреты попадают в код и что реально помогает изменить культуру команды.

Нашёл потери на $17,000 в год: устаревший тариф, забытая нода, нулевой автоскейлинг. Клиент хотел внедрение без аудита. Почему это рулетка с продакшеном.
Bitnami без предупреждения переехали с образами MongoDB и положили тысячи Kubernetes-деплоев. Решение: зеркалить критичные образы в собственный реджистри.
Google закрыл goo.gl в 2018-м без возможности миграции. 15 лет в инфраструктуре — одно правило: бесплатное для экспериментов, критическое под контролем.
Три реальных аудита вскрыли $50k потерь через кладбища снапшотов, зомби-ресурсы и IAM-хаос. Фреймворк ROI для расчёта окупаемости аудита вашей инфраструктуры.
Почему тег :latest — это не «последняя стабильная», а «что сейчас там лежит». Два реальных инцидента: Azure Kubernetes и MongoDB v8 в dev.
Jenkins говорит «успех», а production лежит. Почему pull-based ArgoCD замечает то, что пропускает CI/CD — и кто реально контролирует ваш прод.
В одном AWS аккаунте — 126 IAM пользователей, пароли до 10 лет, MFA не у всех, половина не логинилась годами. Вопрос не лояльности, а статистики.
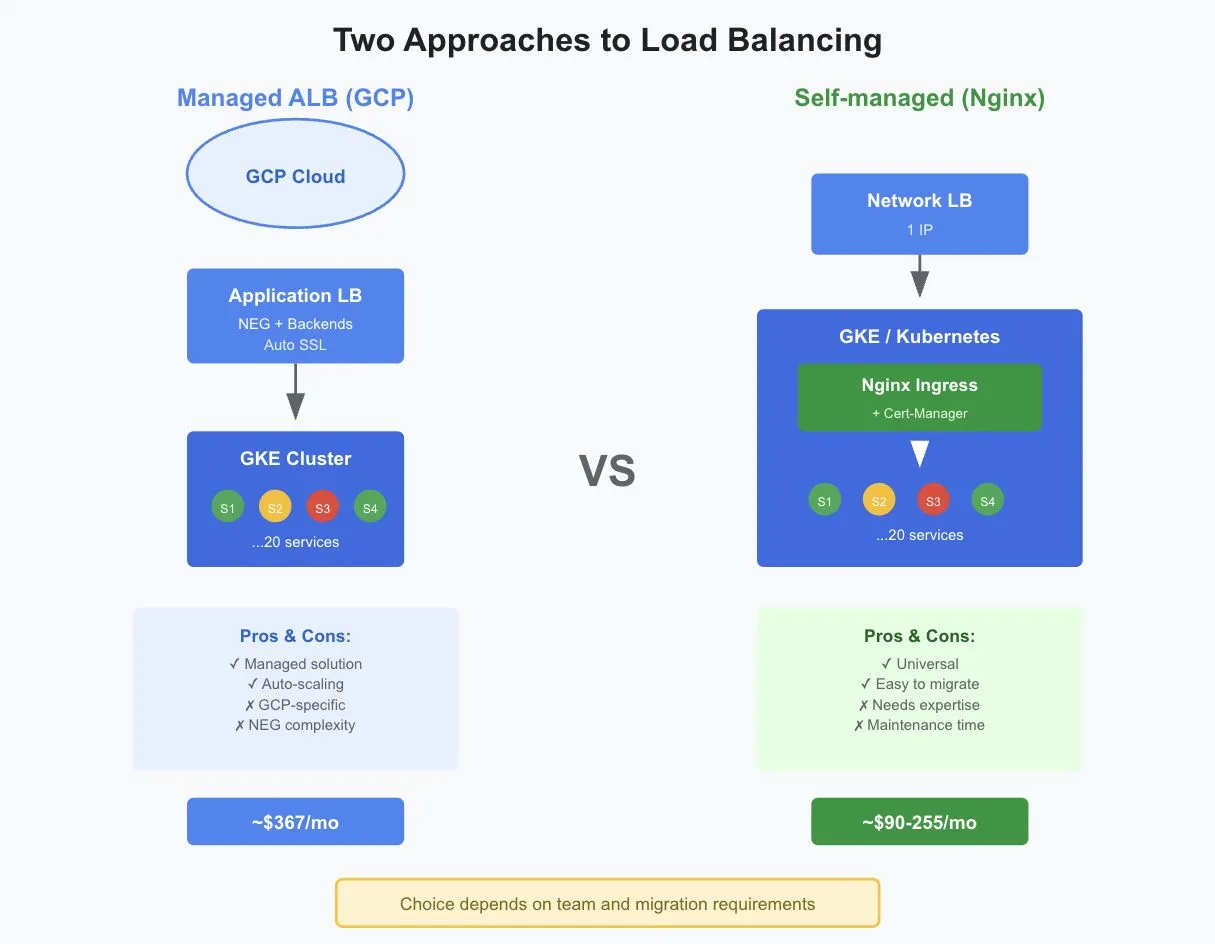
Nginx-Ingress + Cert-Manager внутри GKE против managed ALB: стоимость, компромиссы и когда что выбирать. 20 сервисов за $90-255 вместо $367.
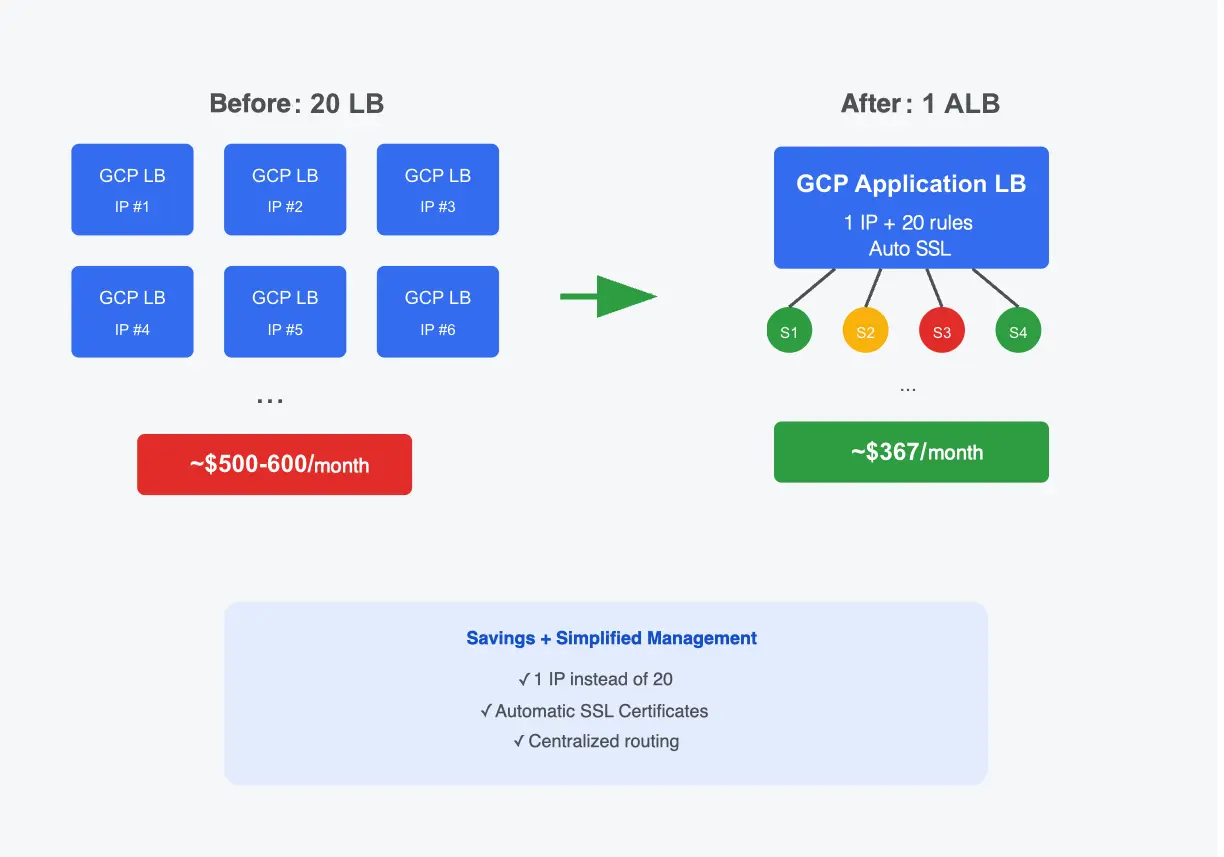
20 микросервисов в GKE, каждый со своим LB: $500-600/месяц. Один Application LB с host-based routing снизил счёт до $367. Как устроена экономия.