A bit of theory on how to sequence your tasks - with real calculations. Written by a DevOps/Cloud/Platform engineer and sysadmin.
The situation:
- Backend team messaged last night: CI/CD broke again on a dev deploy. Third time this week. Two hours lost debugging.
- QA wrote this morning: they need a new environment for a feature. Non-standard config, a regular namespace won’t cut it. They have a deadline - release in two weeks.
- The product manager just popped into Slack: “When will the QA environment be ready? They’re blocked.”
- And there’s still a task from last sprint - set up alerting for a new service. Nobody’s pushing, but the technical debt keeps growing.
Four tasks. Everything is urgent. Where do you start?
Intuition might not help here. (For fun - write down your answer before reading on.)
Let’s walk through the theory. What if your intuition just isn’t trained yet?
Step one: not everything is equally urgent
The first thing to do with any incoming request is not to calculate it. It’s to sort it.
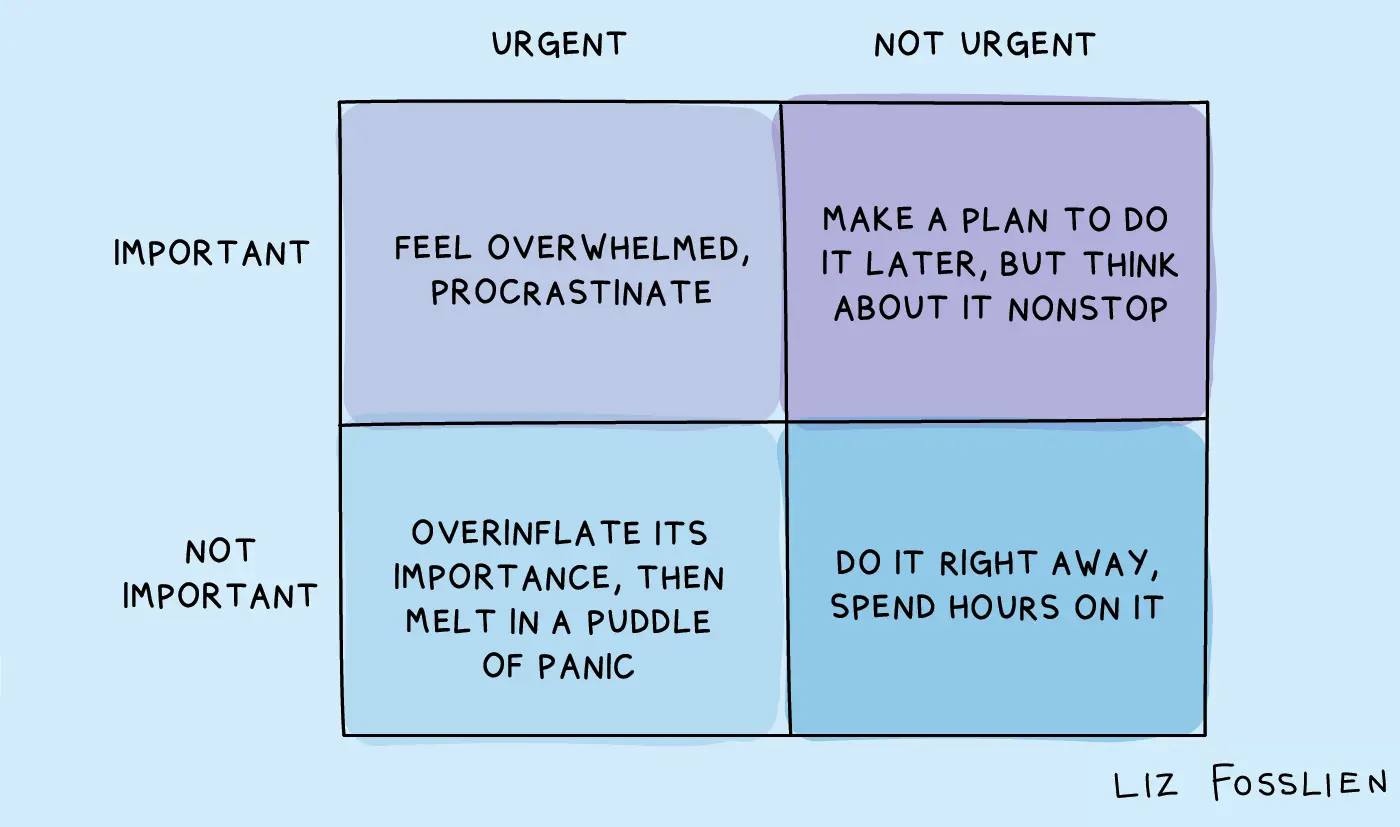
The Eisenhower Matrix splits tasks across two axes: important/not important and urgent/not urgent. Four quadrants.
Quadrant I - Important and urgent. CI/CD is broken in prod right now, team is down. Prod is on fire. No frameworks, no calculations - just fix it.
Quadrant II - Important, but not urgent. Most infra tasks live here. Set up alerting. Fix the flaky CI/CD. Write documentation. These tasks define the quality of your work, but nobody’s breathing down your neck. That’s exactly why they keep getting pushed - and then become Quadrant I.
Stephen Covey called this the “Quadrant II problem”: important non-urgent always loses to urgent non-important.
Quadrant III - Urgent, but not important. “Give me SSH access, urgent.” “Urgent - can you check why my local env is broken.” If it takes five minutes - do it. If not - delegate or defer.
Quadrant IV - Not important and not urgent. “Try that new tool I read about.” Don’t throw it away - slot it into gaps between tasks. It’s an investment in yourself. Pays off, just not today.
Back to our situation.
CI/CD in dev fails every third deploy - Quadrant II. Not prod, the team isn’t blocked right now, but they’re losing two hours every other day.
QA needs an environment - Quadrant II. Deadline in two weeks, not blocking anything today.
The PM pushing in Slack - that’s not a new task, it’s pressure on an existing one.
Alerting - Quadrant II. Nobody pushing.
All three tasks in the same quadrant. Let’s go deeper.
Step two: what matters more - let’s calculate
RICE Framework was invented at Intercom for prioritizing product features. It works for infra tasks too.
Formula: RICE = (Reach × Impact × Confidence) / Effort
Reach - how many people does the task affect per quarter. For infra, I count internal people - dev teams, not end users (I have no idea about those).
Impact - how much. Scale: 0.25 (minimal) / 0.5 / 1 / 2 / 3 (massive). Hardest parameter to nail. Useful categories: slows work down, annoying, blocking, reshuffles the whole team’s priorities?
Confidence - how sure are you of your estimates. 100% / 80% / 50%. Murky task with unclear scope - confidence drops, and the final score drops fairly.
Effort - in person-months. One month = 160 hours. 4 hours = 0.025 person-months.
Calculating CI/CD:
Reach: 10 deploys per week, fails every third - 30+ incidents per quarter. 1-2 people per incident. Total: 30 person-incidents.
Impact: First instinct - give it a 1, “it’s dev, not prod.” But cumulative stress from repeated failures grows. At the quarterly review, the team will say “infra wasn’t working.” I’m giving it 1.5 - between medium and high.
Confidence: I know where to look. 80%.
Effort: I can fix it in 4-8 hours. Backend team on their own - 20+ hours of trial and error. Taking 8 hours = 0.05 person-months.
RICE = (30 × 1.5 × 0.8) / 0.05 = 720
Calculating QA environment:
Reach: Currently 2 QA engineers. If automated - 5 people regularly. For this calculation: 2 people.
Impact: Critical for this release, but QA has other tasks in the meantime. 2.
Confidence: Clear what needs to be done. 90%.
Effort: IaC already exists. Setup takes 4 hours = 0.025 person-months for someone unfamiliar with the environment, or a junior. 1 hour for me = 0.00625 person-months.
RICE = (2 × 2 × 0.9) / 0.025 = 144 RICE = (2 × 2 × 0.9) / 0.00625 = 576
But there’s nobody unfamiliar around - it’s just me. So we take 576.
CI/CD vs QA environment: 720 vs 576. Not even two times the difference, but CI/CD wins.
Now I have a number. I can show it to the PM who’s pushing in Slack. Not “I decided so,” but “here’s the calculation - CI/CD is costing the team more.”
(Do you actually believe that?)
Step three: what if the deadline is tomorrow? Or something else we haven’t accounted for?
This is where you either recalculate RICE - or use something different.
Say the PM tells you the QA environment isn’t needed in two weeks, but in two days. A feature got bumped up, everything shifted.
RICE won’t change. CI/CD is still 720, QA is still 576. (Although… Reach changes, doesn’t it - QA doesn’t exist in a vacuum, they’re testing something for someone. Developers need to fix what QA finds… Bonus exercise: recalculate RICE for the updated deadline.)
Common sense starts to doubt. Which is a good moment to introduce the third tool.
WSJF (Weighted Shortest Job First) - a framework from Scaled Agile. It doesn’t look at task value. It looks at Cost of Delay - what you’re losing every day you don’t do it.
Formula: WSJF = Cost of Delay / Job Duration
Cost of Delay has three components:
- Business/team value
- Time criticality (is there a deadline, a window of opportunity)
- Risk reduction or opportunity enablement
CI/CD: we lose 2 hours of engineering time every other day. Multiply by your hourly rate - real money. No hard deadline, but the losses are accumulating right now. Cost of Delay compounds.
QA environment (new scenario, deadline in 2 days): 2 days = 16 working hours. Task takes 4 hours. QA gets 12 hours for testing. Don’t do it today - they miss the release. Cost of Delay: high and specific.
By WSJF - QA environment first. Because every hour of delay shrinks the testing window.
Here’s what WSJF sees that RICE doesn’t: the difference between “task loses value every day” and “task is waiting for its moment, blocking nobody yet.”
For CI/CD, Cost of Delay is constant. For QA environment - zero, until the deadline hits. Then it’s a cliff.
How it all works together
Three tools, three levels:
Eisenhower - filter at intake. Prod on fire - do it now. Everything else - sort into quadrants.
RICE - sprint or quarterly planning. You have 10 tasks in Quadrant II and need to pick the top 3. Calculate scores, sort.
WSJF - pick right now. Two tasks with similar weight, both can wait - but one has a deadline tomorrow. WSJF tells you which goes first.
And the fourth case - no framework. Prod is on fire. Just fix it.
What I’ve figured out for myself
A long time ago I read “Time Management for System Administrators” by Thomas Limoncelli. One principle stuck - and it’s helped me over and over: creating a user account is not urgent, but it takes five minutes and unblocks another person. Do it now, don’t wait until end of day. Small task, disproportionately large effect.
Intuition works. Its blind spots come from lack of experience.
Like when two tasks feel equal in weight and you don’t have enough reps to tell them apart. Intuition is like a black box running all these calculations - but hiding the process. You get the result, but the chain of reasoning is invisible. It sees accumulated Cost of Delay, if you know what that is.
But it doesn’t give you an argument in a conversation with your manager.
Frameworks aren’t smarter than intuition. They structure what intuition does invisibly. They make a decision explainable - to the team, to the manager, to yourself in a month.
The best answer to “how do you prioritize?” isn’t a list of framework names. It’s being able to explain why this task now, and not that one.
Back to the original situation.
Three tasks. Backend, QA + PM in Slack, alerting.
My order: CI/CD → QA environment → alerting. If QA’s deadline is tomorrow - I flip the first two.
To the PM in Slack: “QA environment - done by lunch. (Tomorrow’s.)”
Not “I decided so.” But “here’s why.”
I do IT infrastructure audits. I find what’s slowing you down - before it becomes an incident. itaudit.yushkov.org
Image: Liz Fosslien