Creators vs Maintainers
Started as a maintainer, always envied creators — until infrastructure became my thing. Now building it from scratch: for free or for hire.
IT infrastructure · DevOps · Cloud
Started as a maintainer, always envied creators — until infrastructure became my thing. Now building it from scratch: for free or for hire.
Two ways to close a port in AWS NACL. Why the "obvious" choice breaks at scale, and how the stateless nature forces explicit port ranges.
Built a custom status page from scratch, on why automation beats alerting — and why a simple script beats AI for predictable failures.
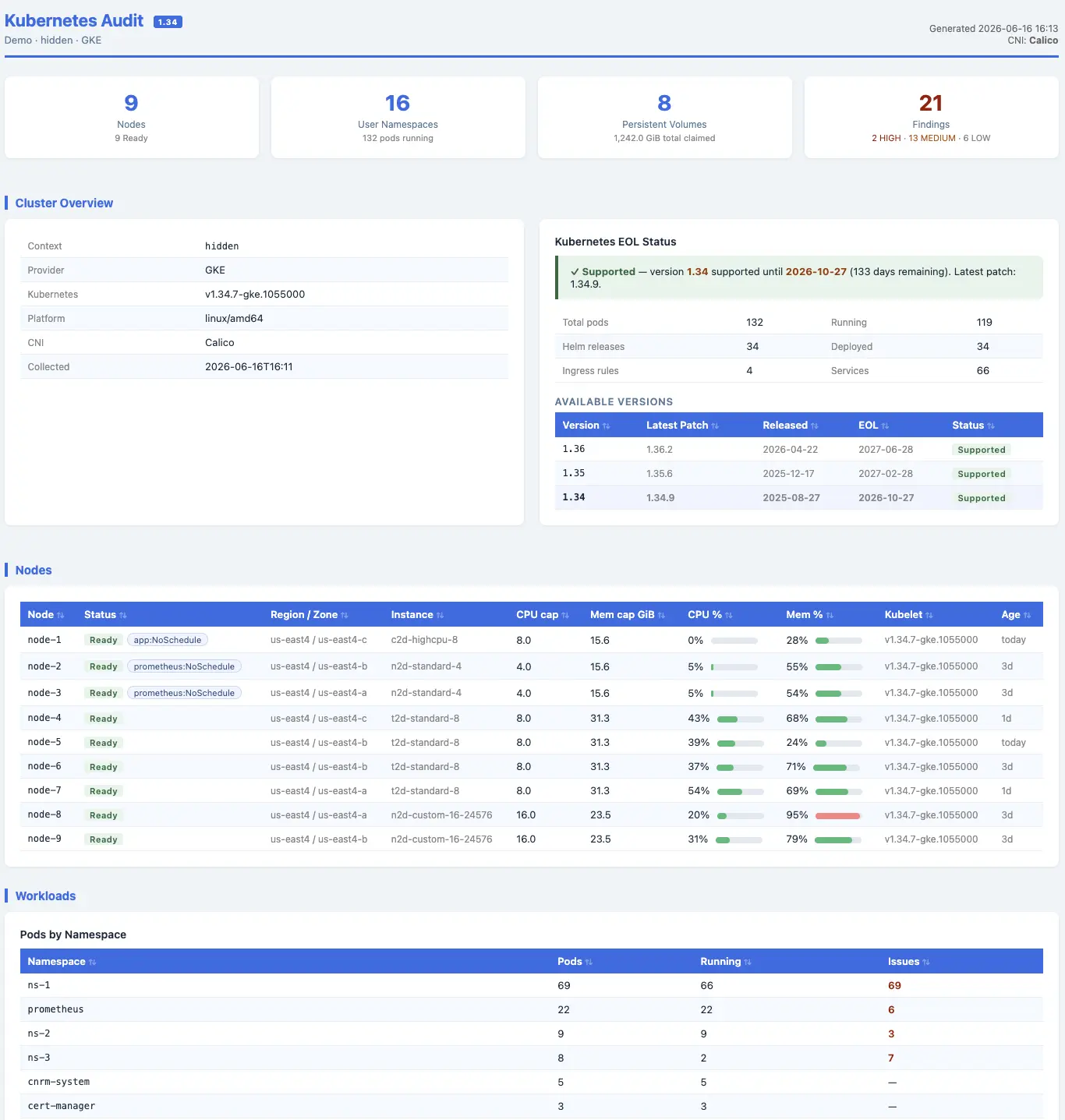
One-time k8s cluster snapshot — no monitoring, no long-running setup. A script that surfaces issues while you're still on the call with a client.
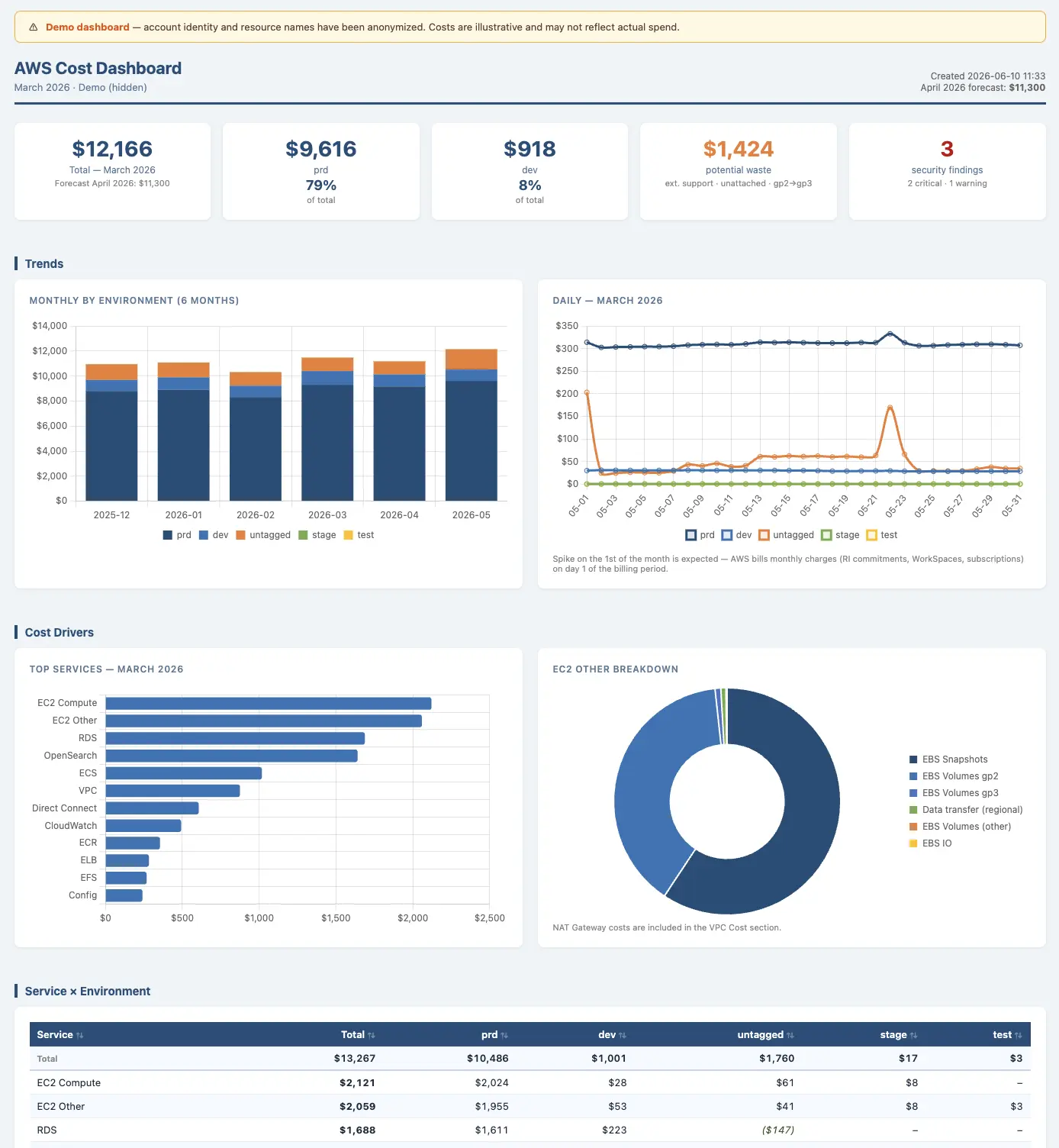
A one-time AWS snapshot that shows exactly where money is leaking. No billing deep-dives, no fear of breaking prod. Every client found waste.
Three types of business owners: successful, dying, and "so-so". I spent a week on the third type. Their response: "this should have been free."
They asked for a star story. There isn't one. A serverless startup, two DevOps engineers, a couple of months. Just regular work — and that's the point.
I tried explaining servers and the cloud to a tech-savvy adult. Complete failure. How do you explain these concepts without jargon or lengthy lectures?
From Windows D drive tricks to Docker containers — the same idea, twenty years apart.

Upgraded OKE cluster from Kubernetes 1.26 to 1.33. Static nodepools, manual AZ config, 14-min pod downtime per node. Four hours later — stopped.
You gave your AI root access? And you're surprised?
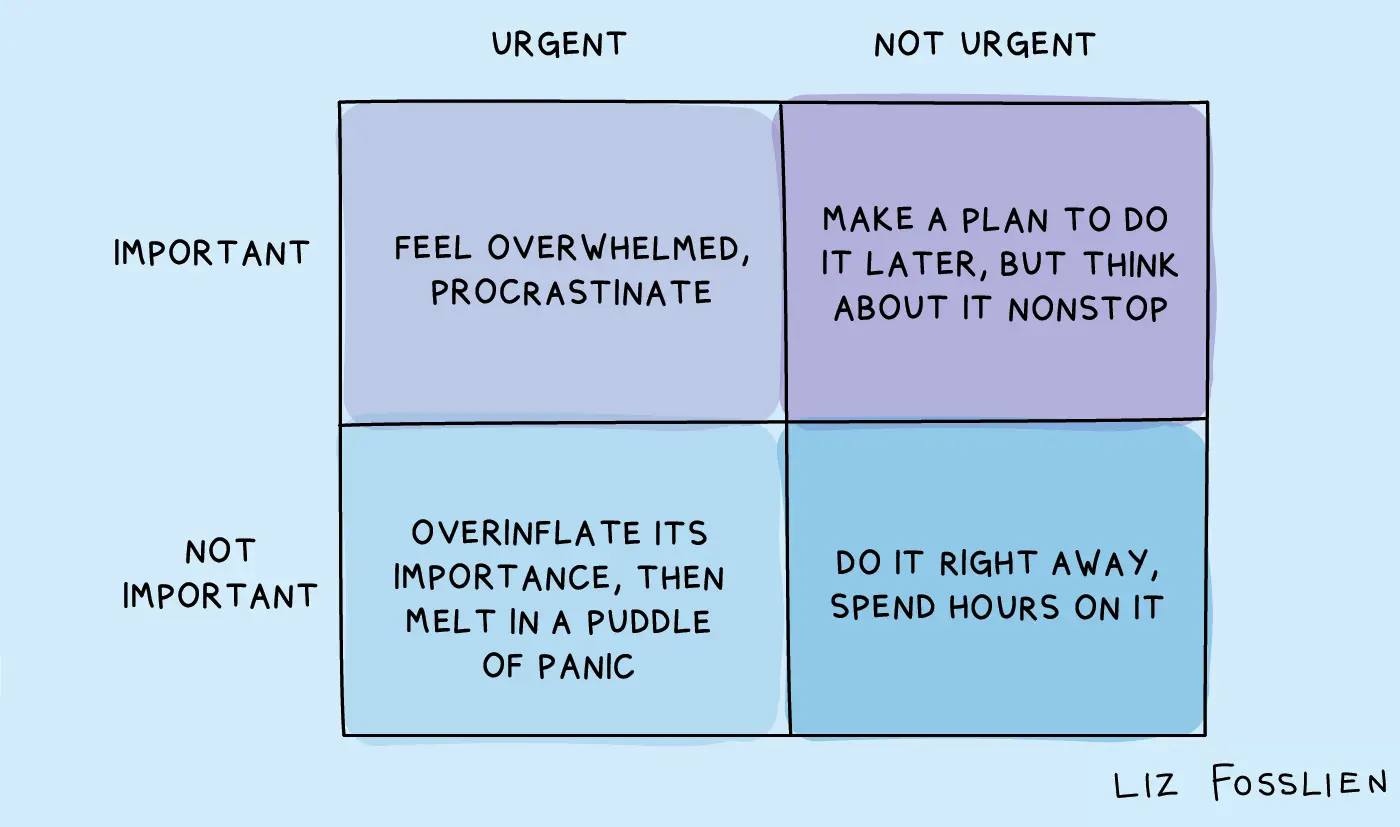
Eisenhower, RICE, WSJF — three prioritization frameworks explained with my DevOps examples. When intuition works but doesn't convince.
You made it work, great! Now let's make it work reliably and cost-efficiently.

Mr. Cody from Interstate 60 kept a notebook for liars. 'Everyone says' on LinkedIn is the same lie — no data, just hype.
Real production cluster: monitoring alone takes 20+ pods and 9.5 GB RAM. What 'free' Prometheus actually costs in resources, time, and attention.
When HA monitoring isn't enough: how a botnet, cardinality explosion, and one Grafana dashboard took down a Thanos cluster replica by replica.
Migrating off S3 may never pay off.
When "prod is down" lands in your chat — the first question isn't what to check. It's which prod. And why assuming AWS is the wrong move.
If your customer told you prod was down before your team did — you don't have production. You have an MVP.
How a hardcoded Helm value triggered an infinite exception loop that filled the disk and took down a managed OVH database. There was a backup. Lucky.
They need Kubernetes. That's not my opinion - I checked.
A company paid $7,000/month for two monitoring tools on AWS-only infrastructure. The reason: nobody had asked why in five years.
I criticized Bitnami Helm charts for being too complex — then wrote my own. Ten iterations later I hit 220 lines. Universality has a price.
2 hours building CodeBuild, Terraform, and VPC endpoints to fix a CircleCI timeout in AWS China. Then I ran the numbers. The simple fix was already there.
Kubernetes cluster node upgrades aren't a button. Drain, upgrade, uncordon — one node at a time. And all of it in one person's head.
Updating infrastructure isn't a button.
From MS Authenticator's giant font to Ubuntu dropping /usr/bin/python — updates break things. This isn't laziness. It's learned pain.
When you agree to a low hourly rate, price determines attitude — in both directions. Here's the system I built to stay sane.

The service went down. Monitoring was silent. The client messaged first. Found a ghost, twelve backup layers, and two bugs that had been cancelling each other out.

When does a dedicated FinOps engineer actually pay off? The math, the authority trap, and what works when your cloud bill is under $500K/year.
A Grigoriy Oster-style guide on how to make your colleagues' lives miserable - and ensure your own job security forever.

How a PM's preference for Grafana cost a startup $2,000/year - and why it still wasn't a failure.
ECS vs EKS real cost breakdown: $73/month fixed EKS control plane plus 20-30% engineer time on maintenance vs. ECS that just works out of the box.
How App Runner's hard 120-second connection timeout broke our video streaming feature - and what to use instead: ECS Fargate or Cloud Run.
A CA certificate on VPN servers expired quietly - no monitoring, no alerts. Here's how to check yours and set up expiration alerts before the incident.

Copy-pasting Kubernetes configs caused a prod outage. Real comparison of Helm, Kustomize, and hybrid approach - deployment errors dropped 80%.

Two real incidents where database connection limits silently killed production - and what connection pooling and monitoring would have prevented.

A :dev library version in production caused an outage 2 days after a perfect CI/CD setup. The case for automatic guardrails over correct configuration.

Same API, 15M requests/month: AWS Lambda $33 vs GCP Cloud Functions $16. Real cost breakdown and why architecture saves more than provider choice.

LDAP admin password committed to a git repo under a variable named PASSWORD. Why credentials end up in code and what actually breaks the cycle.

Client had $17K/year in cloud waste — outdated pricing, idle nodes, zero autoscaling. They wanted fixes without an audit. Here's why that's a gamble.
How Bitnami silently moved MongoDB images to bitnamilegacy overnight, causing mass ImagePullBackOff across Kubernetes clusters. Fix: mirror critical images to your own registry.
Google shut down goo.gl in 2018 with no recovery path. 15 years in infra led to one rule: free for experiments, critical under your control.
Three real audits uncovered $50k in cloud waste through snapshot graveyards, zombie EC2, and IAM sprawl. Includes ROI framework to estimate your savings.
How using :latest tag in Kubernetes cost us hours of dev downtime — twice. Two real incidents and why explicit versions matter in production manifests.
Push-based CI/CD says green while production drifts. Why ArgoCD's pull model catches what Jenkins misses — and who really controls your production.
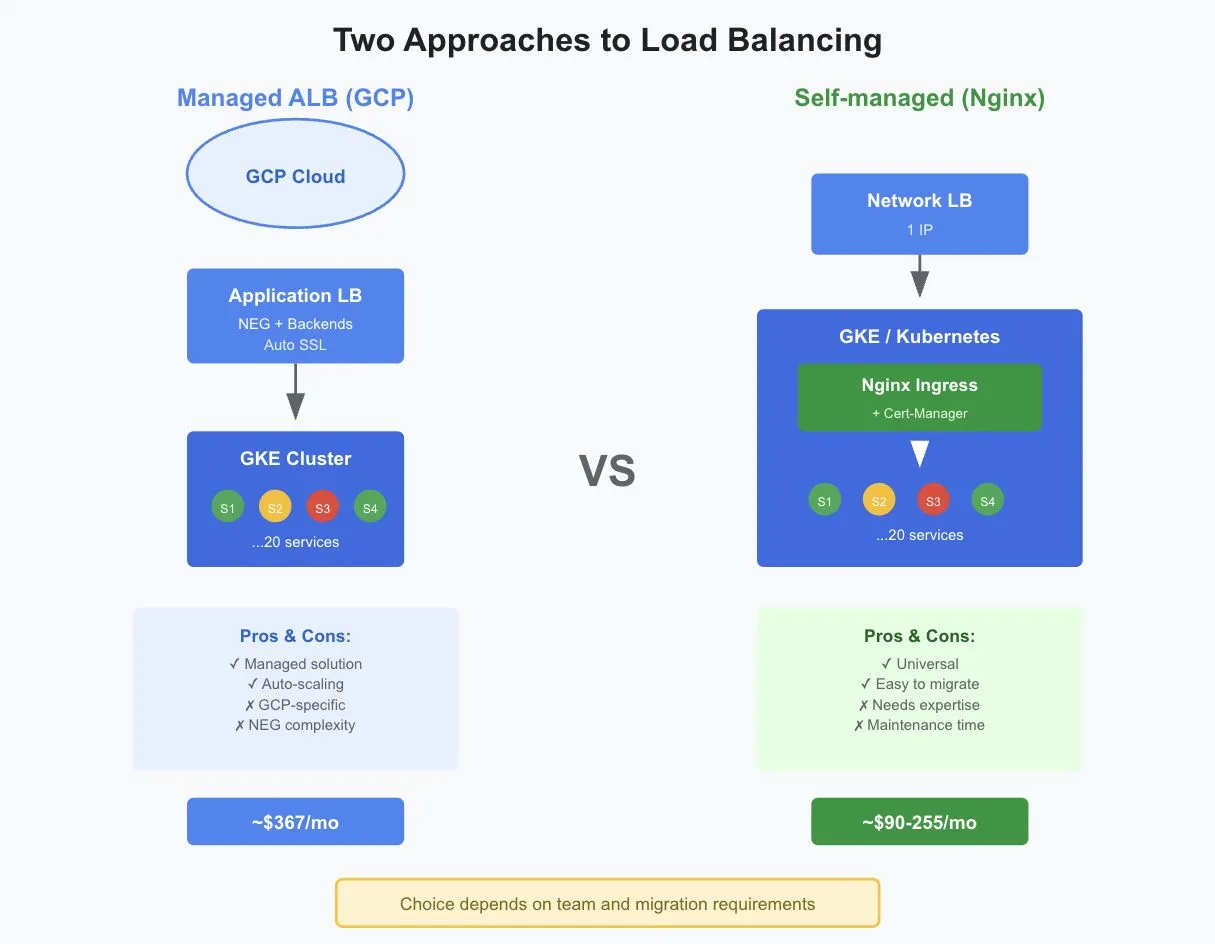
Nginx-Ingress + Cert-Manager in GKE vs managed ALB: cost breakdown, trade-offs, and when to choose each. From $367/month to $40-55 for 20 services.
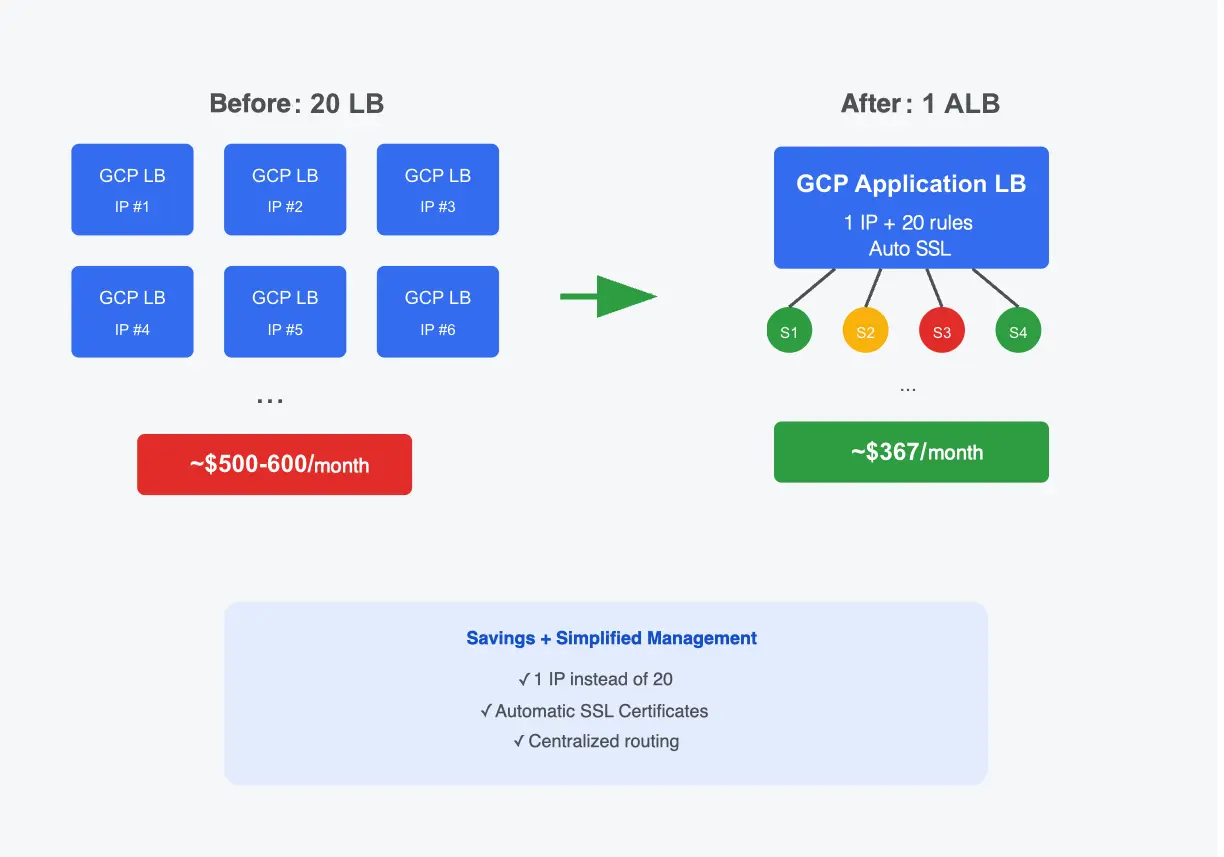
20 microservices in GKE, each with its own Load Balancer: $500-600/month. One Application LB with host-based routing cut the bill to $367 — a 40% saving.